解决CPU100%的问题
现今Web容量规划的大多数做法类似:
问:如何测试桥梁的受重力。
答:不断增加压力直到压断之为止。
若客户要求站点需要支持5000用户同时在线,然后我们一般设计支持5000*10%*1.42并发的系统即可。1.42为系数,可以根据实际问题进行调整,而10%是参考众多的站点数据而来。
软件不像桥梁一样,软件的重新建立甚至不需要花费任何费用,所以上述的方法不失为一个好办法。可是模拟真实环境也意味着你永远跑着问题后面。但是郎咸平教授也说要求完美,是中国即使有四大发明却在现代落后于美国的原因。中国的飞机和人家同一时间研发的,可是人家都出了好几个版本了,我们还一直在研发中。no作no die在Web开发中意味着no作to die。
不完美,意味着需要经常监控Web的各项指标,在出现问题时不断完善之前的设计。
查找系统的瓶颈
容量规划包含前期的设计预计后期的扩展,一个项目上线一年没有太大问题,说明前期的设计并没有问题,最近却偶尔出行cpu100%的问题。
定位问题
个人总结,一般查找性能瓶颈问题,可以从CPU、DISK IO、内存、SWAP这四处着手。cpu 100%的问就题是怀疑网站出现问题,使用上述手段得到的。
1 CPU检查
使用指令top
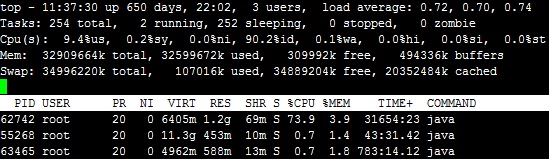
可以看到PID 62742的进程,占用的CPU达73.9,并随之上升至100%以上。如果进一步查看进程的线程,可以在shift+h。或者执行
top -h -p 62742
如下
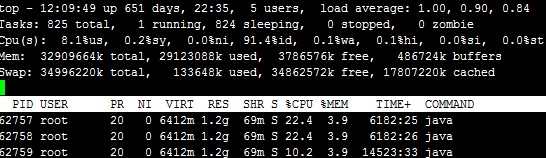
cpu的问题往往都不是CPU的问题,比较绕口,也就是说,绝大多数情况你并不需要升级你的处理器。其往往是由于其它原因造成,我们的例子就是这样的。
2 内存
free -m

虽然使用了20多G,但是还有3g左右,可忽略
- Disk io
iostat -c

iowait仅有0.10,很正常,《Web容量规划的艺术》一书中曾经介绍说,其在运维中发现mysql服务的iowait达到46%时网站出行异常,当他经优化将之降至很小后发现网站读取变正常了。可见这里,iowait等各种指标没有办法设定一个准确的值,40%还是10%代表网站出现了问题,但是如果指标出现大幅的变化,这是一个有用的信号。
- swap
vmsta 1
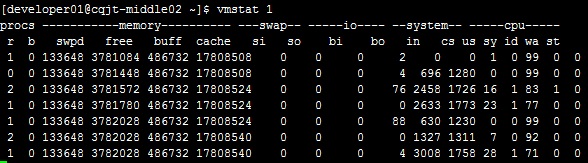
si/so分别代表数据从硬盘移入内存/数据从内存移入硬盘,bi/bo是写/读硬盘的数据。我们知道,一般我们设置swap分区,以在数据不需要或者内存资源不够的时候写入swap(硬盘)以节省内存的空间。我们知道这是一个比较好的策略,毕竟内存是比较宝贵的资源,这也是mysql的软件设计时会充分考虑swap分区使用的原因。但是当内存资源严重不足,或者软件设计的原因造成其不断地需要从硬盘交互数据到内存的时候,这会相比直接从内存读取花费非常长的时间。
上述的指标除了cpu以外均是正常的。
解决CPU100%的问题
造成cpu 100%的进程62742是个java进程,故我们使用jstack工具查看
sudo /usr/java/jdk1.7.0_10/bin/jstack 62742> cpu_100
还记得上面监控结果中,进程62742其线程中占用cpu最大的前三位PID分别为62757、62758、62759,转换成16进制分别为0xf525、0xf526、0xf527。然后再cpu_100的文件中查找
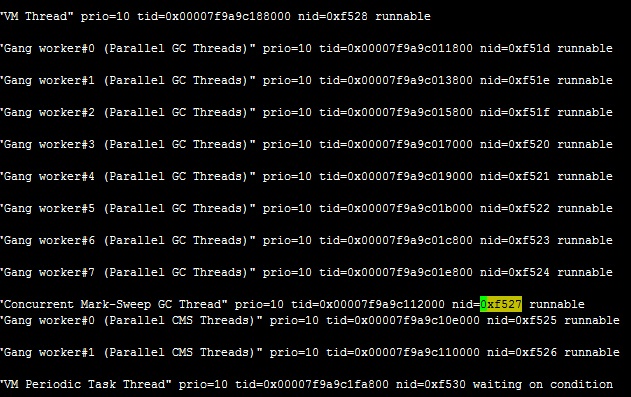
结果中显示上述的三个线程均在GC内存回收。
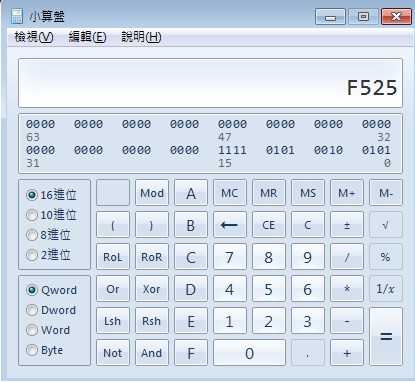
小技巧
如何转化16进制,使用win7自带的计算器即可,具体地在菜单"查看"中选择程序设计师,如下图
现在我们知道是GC造成cpu出现100%,为了处理问题,我们可以加大内存或者优化内存回收算法、以及找到造成GC的代码。
使用jmap查看各种类使用的内存情况
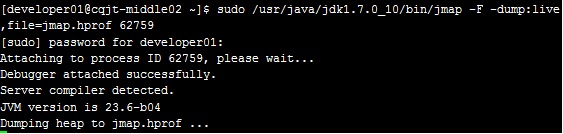
使用eclipse Memory Analyzer(下载)进行分析,结果发现两个问题
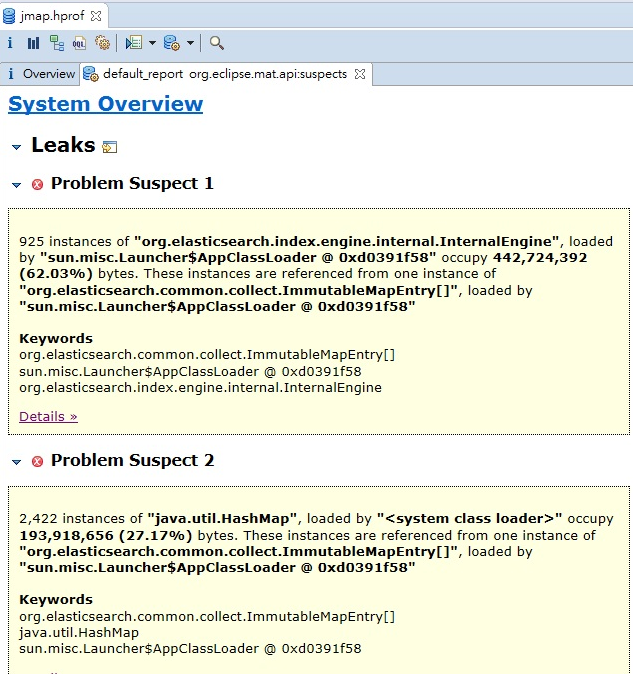
两个问题都与elasticsearch有关,一个流行的检索产品。想起之前为了监控,部署了logstash,其核心点就是使用elasticsearch实现的。由于服务器比较多,我选择比较廉价的方式,将其移走,然后cpu 15分钟后指标就正常了。指标的恢复和其统计的周期有关,哪怕你解决了问题,它也不会马上恢复正常。