如何实现5公里范围内的内容推送
负责的交通行业的解决方案中有这样的一个问题:假设一辆行驶的小汽车A,驾驶员使用我们的产品(手机终端),搜索附近5公里内发生的路况或者其他车主发送的路况信息。

相关技术
路况信息
手机发送的路况信息(或者是从政府部门收集到的路况信息),大多有桩号或者坐标的,桩号同时也是可转换为桩号的。所以坐标是路况信息中比较重要的部分,其它的如发生时间,内容,出行建议等等,重要的还有失效时间。类似于
{"id":"818","subject":"厦成线(山洞隧道进口处方向)","content":"2014年03月04日 09时00分,厦成线(山洞隧道进口处)出现了地质灾害,现已半幅封闭半幅单向通行,预计2014年03月04日 18时00分结束","type":"7","pileScope":"K2392 + 952 至 K2392 + 962","betweenNode":"山洞隧道进口处","eventType":"地质灾害","created_time":"2014-03-04 09:00:00","expectEndTime":"2014-03-04 18:00:00","location":"厦成线 山洞隧道进口处","measures":"半幅封闭半幅单向通行","bypass":"无","gsgdFlag":"G319"}
坐标转换
判断一个坐标A(lati1,lon1)是否在坐标B(lat2,lon2)的五公里以内,以下为java代码
float R = 6371 ;
double equatorLength = 2 * Math.PI * R; // 赤道长度
// 该纬度的经线长度
double localWeftLength = equatorLength * Math.cos(lat2 / 180);
float spaceLong = (float) (5/ (localWeftLength / 360));
float spaceLat = (float) (5/ (equatorLength / 360));
if ((Math.abs(lat1 - lat2) <= spaceLat)
&& (Math.abs(lon1 - lon2) <= spaceLong)) {
return true ;
}
return false ;
以上的算法不能解决问题?
是的,因为车辆的位置总是在移动,假设有平均有100条路况信息在系统中,并且以每小时20条的速度在增加,当有新数据进来时,轮询计算所有的车辆位置,利用上面的算法,对于符合的车辆推送数据。这个算法有个优化:假定行驶的车辆总是恒速的,或者你能接受车辆的位置在某段时间内的位移可以忽略不计。这可以节省计算的频率。
但是这样有个缺点,就是汽车进入新的位置之前,5公里内之前发生了一些路况。以上的算法是不能应对的。
解决思路
这个问题可以分为四点:
路况信息是有失效时间,一半用户只关注半小时以内的路况或者新闻。
车主除了关心最新的5公里以内的信息,同时还关注之前发生的,但是还没失效的路况。
推送的信息不能重复,这点非常重要。
关于push还是pull。
解决问题,我比较喜欢先难后易,
比如问题4,解决思路:
push的方式一是有内容是主动获取车主列表,然后进行判断,成功则推送,这种方式不能推送旧的有效信息;二是定时访问车主列表,然后比对所有的路况信息,判断成功后推送,这种方式可能需要做一些优化,为了避免频繁计算,最好假定车辆的位置在某段时间内不变。其缺点就是高速路情况比较复杂,塞车什么的,不好计算这个时间。特别说明的是,push的方式一般需要采用订阅的方式实现,因为这样才能体现用户的意愿。
pull的方式是车主主动获取5公里内的路况信息(比如打开某个页面请求,放弃则退出页面),和push的第二种方式比较类似,除了轮询,我们还可以使用队列的方式。
这里我们同样可以这样处理,问题是我们如何设计这些队列,比如将内容归类,让用户可以监听到他们关心的内容(5公里以内),对于这个问题,我是由计算机一个思想出发的,那就是计算机处理任何图形的问题,都是从点出发,然后到面,到立体的。
我们可以这样想象
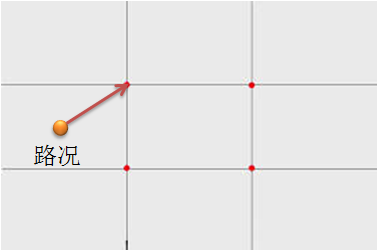
类似五子棋(围棋没下过,不好意思),只允许把棋子放在交点部分,以5公里为例,坐标距离略小于0.05f,我们可以将其想象为有25个交点的方形,期间任何一个点都能找个距离自己最近的那个交点。
这样采用pull的方式就是这样的,任何一个路况(坐标)都能找到一个交点,并作为一个队列,这样我们就有很多这样的队列;然后每个用户都同时监听25个队列,采用pull的方式,只要每次将25个队列的内容取到,去除重与复即可。我们打算使用比较熟悉的redis来实现这个功能。
开始之前,我们需要进行容量规划。
一个路况信息,采用key:value的方式存储,大概512Byte。一般不会有超过1000条信息,也就是不会超过0.5M的内存。
接下来,我们解决问题3,如何避免重复。
选择redis,除了其性能非常棒以外,还有一点就是其支持的数据类型非常丰富,比如其Set类型的支持,有一个函数SDIFF与SDIFFSTORE
,这两个方法可以帮你分析两个集合之前的差异,我们可以针对每个用户,保留两个推送队列,一个是上次推送的,一个是本次需要推送的,这样就可以获得不重复的推送队列
容量规划
假设有5000个在线用户,并假设每个用户都接收到所有的信息,使用的容量大约为5000*2*4*1000Byte+0.5M。不到50M的内存,这只要使用一般的Server都很愉快的接受的。
或许你会有疑问,为什不是5000*2*0.5呢,那是因为我们是将内容先采用简单key:value的方式保存,value大约512Byte,但是key却只有4Byte,每次都将key发送到队列即可。
现在解决问题1和2
一般的nosql都能解决这个问题,就是设置失效时间
jedis.set(key, value);
jedis.expire(key, timeout);//设置失效时间
我们将内容单独保存,采用最直接的key:value方式(value可能为gson字符的对象字符串);然后将key推送至队列,这样用户获取队列后,再逐步获取最终的gson字串,将其反序列为对象。或许你还有疑问,如果一开始对内容设置失效时间,但是队列没有失效时间,这样会获取的null的结果啊。没错,我们也是以此来剔除失效的信息,而且我们的队列是按时间失效的栈一样的存储方式--后进先出,一旦我们获取的空值时,就没有必要再继续下去了,因为后面一定是空值
 至此,所有的问题都解决了。
至此,所有的问题都解决了。
总结
厨师的最高境界是炒豆干,这是大道至简的道理,我觉得计算机也应当如此,解决方案并不一定都得大架构、大数据分析什么的。采用简单的方式,结合现有的资源,能有效地解决问题,也是非常愉快的。